- Распознавание эмоций с помощью сверточной нейронной сети
- Главные препятствия
- Описание проекта
- Описание данных
- Извлечение признаков
- Архитектура модели по умолчанию
- Мой эксперимент
- Разведочный анализ данных
- Наблюдение
- Повторение эксперимента
- Тест производительности
- Производительность новой модели
- Увеличение (аугментация)
- Мужчины, 5 классов
- Объединяем несколько методов
- Тестируем аугментацию на мужчинах
- Мужчины, 2 класса
- Заключение
- Рынок систем детекции и распознавания: Эмоции и «эмоциональные вычисления»
- Системы распознавания эмоций (EDRS)
- Affective computing — «эмоциональные вычисления»
- Будущее
Распознавание эмоций с помощью сверточной нейронной сети

Распознавание эмоций всегда было захватывающей задачей для ученых. В последнее время я работаю над экспериментальным SER-проектом (Speech Emotion Recognition), чтобы понять потенциал этой технологии – для этого я отобрал наиболее популярные репозитории на Github и сделал их основой моего проекта.
Прежде чем мы начнем разбираться в проекте, неплохо будет вспомнить, какие узкие места есть у SER.
Главные препятствия
Описание проекта
Использование сверточной нейронной сети для распознавания эмоций в аудиозаписях. И да, владелец репозитория не ссылался ни на какие источники.
Описание данных
Есть два датасета, которые использовались в репозиториях RAVDESS и SAVEE, я только лишь адаптировал RAVDESS в своей модели. В контекста RAVDESS есть два типа данных: речь (speech) и песня (song).
- 12 актеров и 12 актрис записали свою речь и песни в своем исполнении;
- у актера #18 нет записанных песен;
- эмоции Disgust (отвращение), Neutral (нейтральная) и Surprises (удивленние) отсутствуют в «песенных» данных.
Разбивка по эмоциям:
Диаграмма распределения эмоций:
Извлечение признаков
Когда мы работаем с задачами распознавания речи, мел-кепстральные коэффициенты (MFCCs) – это передовая технология, несмотря на то, что она появилась в 80-х.
Эта форма определяет, каков звук на выходе. Если мы можем точно обозначить форму, она даст нам точное представление прозвучавшей фонемы. Форма речевого тракта проявляет себя в огибающей короткого спектра, и работы MFCC – точно отобразить эту огибающую.
Мы используем MFCC как входной признак. Если вам интересно разобраться подробнее, что такое MFCC, то этот туториал – для вас. Загрузку данных и их конвертацию в формат MFCC можно легко сделать с помощью Python-пакета librosa.
Архитектура модели по умолчанию
Автор разработал CNN-модель с помощь пакет Keras, создав 7 слоев – шесть Con1D слоев и один слой плотности (Dense).
Автор закомментировал слои 4 и 5 в последнем релизе (18 сентября 2018 года) и итоговый размер файла этой модели не подходит под предоставленную сеть, поэтому я не смогу добиться такого же результат по точности – 72%.
Модель просто натренирована с параметрами batch_size=16 и epochs=700 , без какого-либо графика обучения и пр.
Здесь categorical_crossentropy это функция потерь, а мера оценки – точность.
Мой эксперимент
Разведочный анализ данных
В датасете RAVDESS каждый актер проявляет 8 эмоций, проговаривая и пропевая 2 предложения по 2 раза каждое. В итоге с каждого актера получается 4 примера каждой эмоции за исключением вышеупомянутых нейтральной эмоции, отвращения и удивления. Каждое аудио длится примерно 4 секунды, в первой и последней секундах чаще всего тишина.
Наблюдение
После того как я выбрал датасет из 1 актера и 1 актрисы, а затем прослушал все их записи, я понял, что мужчины и женщины выражают свои эмоции по-разному. Например:
- мужская злость (Angry) просто громче;
- мужские радость (Happy) и расстройство (Sad) – особенность в смеющемся и плачущем тонах во время «тишины»;
- женские радость (Happy), злость (Angry) и расстройство (Sad) громче;
- женское отвращение (Disgust) содержит в себе звук рвоты.
Повторение эксперимента
Автор убрал классы neutral, disgust и surprised, чтобы сделать 10-классовое распознавание датасета RAVDESS. Пытаясь повторить опыт автора, я получил такой результат:
Однако я выяснил, что имеет место утечка данных, когда датасет для валидации идентичен тестовому датасету. Поэтому я повторил разделение данных, изолировав датасеты двух актеров и двух актрис, чтобы они не были видны во время теста:
- актеры с 1 по 20 используются для сетов Train / Valid в соотношении 8:2;
- актеры с 21 по 24 изолированы от тестов;
- параметры Train Set: (1248, 216, 1);
- параметры Valid Set: (312, 216, 1);
- параметры Test Set: (320, 216, 1) — (изолировано).
Я заново обучил модель и вот результат:
Тест производительности
Из графика Train Valid Gross видно, что не происходит схождение для выбранных 10 классов. Поэтому я решил понизить сложность модели и оставить только мужские эмоции. Я изолировал двух актеров в рамках test set, а остальных поместил в train/valid set, соотношение 8:2. Это гарантирует, что в датасете не будет дисбаланса. Затем я тренировал мужские и женские данные отдельно, чтобы провести тест.
- Train Set – 640 семплов от актеров 1-10;
- Valid Set – 160 семплов от актеров 1-10;
- Test Set – 160 семплов от актеров 11-12.
Опорная линия: мужчины
- Train Set – 608 семплов от актрис 1-10;
- Valid Set – 152 семпла от актрис 1-10;
- Test Set – 160 семплов от актрис 11-12.
Опорная линия: женщины
Как можно заметить, матрицы ошибок отличаются.
Мужчины: злость (Angry) и радость (Happy) – основные предугаданные классы в модели, но они не похожи.
Женщины: расстройство (Sad) и радость (Happy) – основыне предугаданные классы в модели; злость (Angry) и радость (Happy) легко спутать.
Вспоминая наблюдения из Разведочного анализа данных, я подозреваю, что женские злость (Angry) и радость (Happy) похожи до степени смешения, потому что их способ выражения заключается просто в повышении голоса.
Вдобавок ко всему, мне интересно, что если я еще больше упрощу модель, остави только классы Positive, Neutral и Negative. Или только Positive и Negative. Короче, я сгруппировал эмоции в 2 и 3 класса соответственно.
- Позитивные: радость (Happy), спокойствие (Calm);
- Негативные: злость (Angry), страх (fearful), расстройство (sad).
3 класса:
- Позитивные: радость (Happy);
- Нейтральные: спокойствие (Calm), нейтральная (Neutral);
- Негативные: злость (Angry), страх (fearful), расстройство (sad).
До начала эксперимента я настроил архитектуру модели с помощью мужских данных, сделав 5-классовое распознавание.
Я добавил 2 слоя Conv1D, один слой MaxPooling1D и 2 слоя BarchNormalization; также я изменил значение отсева на 0.25. Наконец, я изменил оптимизатор на SGD со скоростью обучения 0.0001.
Для тренировки модели я применил уменьшение «плато обучения» и сохранил только лучшую модель с минимальным значением val_loss . И вот каковы результаты для разных целевых классов.
Производительность новой модели
Мужчины, 5 классов
Мужчины, 2 класса
Мужчины, 3 класса
Увеличение (аугментация)
Когда я усилил архитектуру модели, оптимизатор и скорость обучения, выяснилось, что модель по-прежнему не сходится в режиме тренировки. Я предположил, что это проблема количества данных, так как у нас имеется только 800 семплов. Это привело меня к методам увеличения аудио, в итоге я увеличил датасеты ровно вдвое. Давайте взглянем на эти методы.
Мужчины, 5 классов
Динамическое увеличение значений
Настройка высоты звука
Добавление белого шума
Заметно, что аугментация сильно повышает точность, до 70+% в общем случае. Особенно в случае с добавлением белого, которое повышает точность до 87,19% – однако тестовая точность и F1-мера падают более чем на 5%. И тут мне ко пришла идея комбинировать несколько методов аугментации для лучшего результата.
Объединяем несколько методов
Белый шум + смещение
Тестируем аугментацию на мужчинах
Мужчины, 2 класса
Белый шум + смещение
Для всех семплов
Белый шум + смещение
Только для позитивных семплов, так как 2-классовый сет дисбалансированный (в сторону негативных семплов).
Настройка высоты звука + белый шум
Для всех семплов
Настройка высоты звука + белый шум
Только для позитивных семплов
Заключение
В конце концов, я смог поэкспериментировать только с мужским датасетом. Я заново разделил данные так, чтобы избежать дисбаланса и, как следствие, утечки данных. Я настроил модель на эксперименты с мужскими голосами, так как я хотел максимально упростить модель для начала. Также я провел тесты, используя разные методы аугментации; добавление белого шума и смещение хорошо зарекомендовали себя на дисбалансированных данных.
Источник
Рынок систем детекции и распознавания: Эмоции и «эмоциональные вычисления»
В наши дни технологии по распознаванию перестают быть недосягаемыми. Распознавание эмоций и «эмоциональные вычисления» являются частью большого пласта науки, также включающего такие основополагающие понятия, как распознавание образов и обработка визуальной информации. Этим постом мы хотим открыть наш блог на Хабре и провести небольшой обзор решений, представленных на рынке систем распознавания эмоций — взглянем, какие компании работают в этом сегменте и чем конкретно они занимаются.
Системы распознавания эмоций (EDRS)
Рынок систем детекции и распознавания эмоций (EDRS) активно развивается. По оценкам ряда экспертов, он продемонстрирует среднегодовой рост в 27,4% и достигнет планки 29,1 млрд долларов к 2022 году. Такие цифры вполне оправданны, поскольку программное обеспечение для распознавания эмоций уже позволяет определять состояние пользователя в произвольный момент времени при помощи веб-камеры или специализированного оборудования, параллельно анализируя поведенческие паттерны, физиологические параметры и изменения настроения пользователя.
Системы, считывающие, транслирующие и распознающие данные эмоциональной природы, можно разбить на группы по типу определения реакций: по физиологическим показателям, мимике, языку тела и движениям, а также по голосу [о последних двух вариантах определения реакций мы более подробно поговорим в последующих материалах].
К физиологии как источнику информации об эмоциях человека нередко прибегают в клинических испытаниях. Например, этот способ детекции эмоций был встроен в метод БОС (биологической обратной связи), когда пациенту на экран монитора компьютера «возвращаются» текущие значения его физиологических показателей, определяемых клиническим протоколом: кардиограмма, частота сердечных сокращений, электрическая активность кожи (ЭАК) и др.
Подобные приемы нашли применение и в других сферах. Например, определение эмоций по физиологическим данным является ключевой функцией устройства MindWave Mobile от NeuroSky, которое надевается на голову и запускает встроенный датчик мозговой активности. Он фиксирует степень концентрации, расслабления либо беспокойства человека, оценивая ее по шкале от 1 до 100. MindWave Mobile адаптирует способ регистрации ЭЭГ, принятый в научных исследованиях. Только в этом случае система оснащена всего одним электродом, в отличие от лабораторных установок, где их количество превышает десять.
Примером детекции эмоциональных реакций по мимике может служить сервис FaceReader нидерландской компании Noldus Information Technology. Программа способна интерпретировать микроэкспрессии лица, распределяя их по семи основным категориям: радость, грусть, гнев, удивление, страх, отвращение и нейтральная (neutral). Кроме того, FaceReader умеет с достаточно высокой точностью определять по лицам возраст и пол человека.
Принципы работы программы базируются на технологиях компьютерного зрения. В частности, речь идет о методе Active Template, заключающемся в наложении на изображение лица деформируемого шаблона, и методе Active Appearance Model, позволяющем создавать искусственную модель лица по контрольным точкам с учетом деталей поверхности. По словам разработчиков, классификация происходит посредством нейронных сетей с тренировочным корпусом в 10 тыс. фотографий.
В этой области заявили о себе и крупные корпорации. Например, компания Microsoft занимается развитием собственного проекта под названием Project Oxford — набора готовых REST API, реализующих алгоритмы машинного зрения (и не только). Программное обеспечение умеет различать по фотографии такие эмоции, как гнев, презрение, отвращение, страх, счастье, грусть и удивление, а также сообщать пользователю об отсутствии каких-либо зримо выраженных эмоций.
Важно отметить тот факт, что над системами распознавания эмоций работают и российские компании. Например, на рынке представлена EDR-система EmoDetect. Программное обеспечение решения способно определять психоэмоциональное состояние человека по выборке изображений (или видео). Классификатор выявляет шесть базовых эмоций — уже упомянутые выше радость, удивление, грусть, злость, страх и отвращение.
Распознавание ведется на основе 20 информативных локальных признаков лица, характеризующих психоэмоциональное состояние человека (ASM). Также производятся расчет двигательных единиц и их классификация по системе кодирования лицевых движений П. Экмана (FACS Action Units). Помимо этого, решение строит графики динамического изменения интенсивности эмоций испытуемого во времени и формирует отчеты о результатах обработки видео.
Кроме того, в рамках этого поста нельзя обойти стороной и тему отслеживания эмоций по данным движений глаз, основные параметры которых — это фиксации и саккады. Наиболее распространенный метод их регистрации носит название видеоокулография (или айтрекинг, более привычная калька с английского термина), принцип которой заключается в записи видео движения глаза с высокой частотой. В видеоокулографии имеется и свой инструментарий — айтрекеры, задействованные в экспериментальных исследованиях разного типа.
Так, компания Neurodata Lab совместно с командой разработчиков из Ocutri создала прототип софтового айтрекера Eye Catcher 0.1, позволяющего извлекать данные движений глаз и головы из видеофайлов, записанных на обычную камеру. Эта технология открывает новые горизонты в изучении движений глаз человека в естественных условиях и ощутимо расширяет исследовательские возможности. Помимо этого, линейки айтрекинговых устройств выпускают такие компании глобального значения, как SR Research (EyeLink), Tobii, SMI (приобретенная на днях корпорацией Apple), а также GazeTracker, Eyezag, Sticky и др. Основным рабочим инструментом последних тоже является веб-камера.
К сегодняшнему дню видеоокулография применяется как в науке, так и в игровой индустрии и онлайн-маркетинге (нейромаркетинге). Решающее значение при покупке в онлайн-магазине играет месторасположение информации о продукте, способствующей конверсии. Требуется и досконально учитывать позиции баннеров и прочей визуальной рекламы.
Например, Google работает над оформлением поверхностей отображения на странице выдачи с использованием айтрекинга, чтобы генерировать максимально эффективные предложения для рекламодателей. Окулография предлагает обоснованный, корректный метод анализа, оказывающий значительную практическую помощь веб-дизайнерам и способствующий тому, чтобы информация above the fold лучше воспринималась пользователями.
Affective computing — «эмоциональные вычисления»
Ключевой вектор развития внедряемых в жизнь человека новых информационных технологий — это улучшение человеко-машинного взаимодействия — human-computer interaction (HCI). Появление EDR-систем привело к возникновению такого понятия, как эмоциональные вычисления, или же по устоявшейся англоязычной терминологии — affective computing. Affective computing — это вид HCI, при котором устройство способно детектировать и соответствующим образом реагировать на чувства и эмоции пользователя, определяемые по мимике, позе, жестам, речевым характеристикам и даже температуре тела. Любопытны в связи с этим и решения, обращающиеся к подкожному кровотоку (как это делает канадский стартап NuraLogix).
Количество проводимых исследований и объемы финансирования говорят о том, что это направление является чрезвычайно перспективным. По данным marketsandmarkets.com, рынок affective computing вырастет с 12,2 млрд долларов в 2016 году до 54 млрд долларов к 2021 году при среднегодовом темпе роста 34,7%, хотя львиная его доля, как и ранее, останется за ведущими игроками рынка (Apple, IBM, Google, Facebook, Microsoft и др.).
Признание статуса эмоциональных вычислений как самостоятельной научно-исследовательской ниши и рост публичного интереса к этой сфере наблюдается приблизительно с 2000 года, когда Розалинд Пикард (Rosalind Picard) опубликовала свою книгу под знаковым названием «Affective Computing» — именно эта монография положила начало профильным исследованиям в MIT. Позднее к ним подключились ученые и из других стран.
Информация в нашем мозгу эмоционально предопределена, и мы часто принимаем решения просто под воздействием того или иного эмоционального импульса. Именно поэтому Пикард в своей книге представила идею конструирования машин, которые были бы непосредственно связаны с человеческими эмоциями и даже способны оказывать на них воздействие.
Наиболее обсуждаемым и распространенным подходом к созданию приложений affective computing является построение когнитивной модели эмоций. Система генерирует эмоциональные состояния и соответствующие им экспрессии на основании набора принципов [формирования эмоции], вместо строгого набора пар «сигнал — эмоция». Её также часто объединяют с технологией распознавания эмоциональных состояний, которая ориентируется на признаки и сигналы, проявляющиеся на нашем лице, теле, коже и т. д. На изображении ниже представлены несколько эмоций, классифицируемых по мимическому каналу:

Эмоции: злость, страх, отвращение, удивление, счастье и грусть (источник)
Эмоции считаются определяемыми процессами. Поэтому задачей affective computing становится достижение взаимодействия с пользователем в манере, приближенной к обыденному человеческому общению — машина должна подстраиваться под эмоциональное состояние пользователя и влиять на него. Для такого подхода были даже придуманы правила, сформулированные американскими исследователями Ортони, Клором и Коллинзом (Ortony, Clore and Collins).

Среди релевантных примеров систем «эмоциональных вычислений» стоит выделить работу Розалинд Пикард и её коллег. С целью повышения результативности обучения студентов учеными была предложена оригинальная эмоциональная модель, построенная на базе циклической модели Рассела. В конечном счете они хотели создать электронного компаньона, отслеживающего эмоциональное состояние студента и определяющего, необходима ли ему помощь в процессе освоения новых знаний.
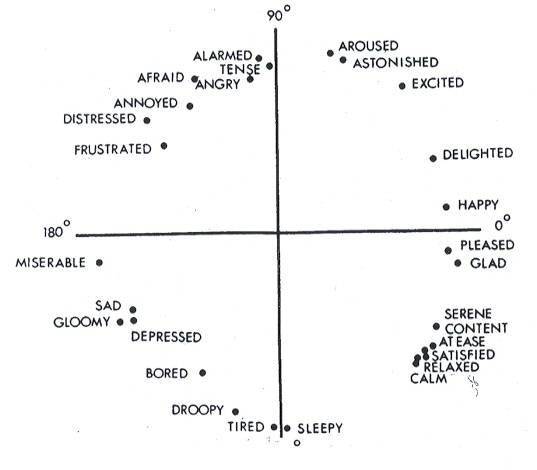
Циклическая модель Рассела (источник)
Интересным применением программных решений, разрабатываемых группой Пикард в MIT, является обучение детей, страдающих аутизмом, определению собственных эмоций и эмоциональных состояний окружающих людей. Все это послужило стимулом к возникновению компании Empatica, которая предлагает потребителям (в том числе больным эпилепсией) носимые браслеты под брендом Embrace, регистрирующие кожно-гальванический рефлекс (GSR) и позволяющие в реальном времени мониторить качество сна, а также уровни стресса и физической активности.
Еще одна компания, у истоков которой стояли Розалинд Пикард и её аспирантка из MIT Рана Эль Калибу (Rana el Kaliouby), носит название Affectiva. Разработчики компании выложили свой SDK на платформе Unity, открыв доступ сторонним разработчикам для экспериментов, тестов и реализации всевозможных микропроектов. В активе у компании на текущий момент крупнейшая в мире база проанализированных лиц — более пяти миллионов экземпляров, а также опыт первопроходца в ряде индустрий, где до того технология распознавания эмоций практически не принималась в расчет, однако анализ по-прежнему ведется только в пределах шести базовых эмоций и одного канала (микроэкспрессии лица).
В этом русле в наши дни развиваются многие лаборатории и стартапы. Например, Sentio Solutions разрабатывает браслет Feel, отслеживающий, распознающий и собирающий данные об испытываемых человеком эмоциях в течение дня. Одновременно мобильное приложение предлагает рекомендации, которые должны сформировать у пользователя положительные, с эмоциональной точки зрения, привычки. Встроенные в браслет сенсоры мониторят сразу несколько физиологических сигналов, таких как пульс, кожно-гальванические реакции, температуру кожи, а алгоритмы системы переводят биологические сигналы на «язык» эмоций.
Стоит упомянуть и компанию Emteq. Их платформа Faceteq не только способна отслеживать состояние водителя автомобиля [усталость], но и используется в медицинских целях — специальное приложение оказывает практическое содействие людям, страдающим от паралича лицевого нерва. Ведутся работы и по внедрению решения в сферу виртуальной реальности, что позволит VR-шлему проецировать эмоциональные реакции пользователя на аватар.
Будущее
Сегодня, в 2017 году, стратегической целью исследований в области «эмоциональных вычислений» и EDRS является выход за пределы узких рамок моно- или биканальной логики, что позволит приблизиться к реальным, а не сугубо декларируемым (положим, механически объединяющим микроэкспрессии с носимыми биодатчиками или айтрекингом), сложным мультимодальным технологиям и методам распознавания эмоциональных состояний.
Компания Neurodata Lab как раз и специализируется на разработке высокоинтеллектуальных технологических решений по распознаванию эмоций и внедрении технологий EDRS в различные отрасли экономики: масс-маркетные проекты, интернет вещей (IoT), робототехнику, индустрию развлечений, интеллектуальные транспортные системы и цифровую медицину.
При этом наблюдается плавный переход от анализа статических фотографий и изображений к динамике аудиовидеопотока и коммуникативной среды в разнообразных её проявлениях. Все это задачи нетривиальные, решающие многие узловые проблемы отрасли и требующие проведения углубленных исследований, сбора огромных массивов данных и комплексной интерпретации реакций человеческого тела (вербальных и невербальных).
Людям неинтересно общаться с неэмоциональными агентами, со стороны которых нет никакой эмоциональной отдачи, никакого отклика. Ученые прикладывают значительные силы, чтобы кардинально изменить ситуацию, однако они сталкиваются с определёнными сложностями. Одна из них — отсутствие в вычислительных системах нейронов. Внутри таких систем имеются только алгоритмы, и это объективная данность.
Человечество пытается понять, каким образом формируются те или иные психологические феномены, чтобы воспроизвести их внутри вычислительных систем. Например, этим занимается правительство США, разрабатывая архитектуру TrueNorth, в основе которой лежат нейробиологические принципы. Процессор имеет неклассическую архитектуру, то есть не придерживается архитектуры фон Неймана, а вдохновлен некоторыми моделями работы неокортекса (о чем подробно рассказывает в своих текстах Курцвейл).
В будущем [а оно может оказаться и не столь далеким, как кажется на первый взгляд] прогресс подобных технологий даст возможность сконструировать самообучающиеся системы, не нуждающиеся в программировании. К ним придется применять совершенно иные техники обучения. И нельзя исключать того, что в результате развитие вычислительной техники пойдет совсем в другую сторону.
Источник