- Введение в задачу распознавания эмоций
- Что такое эмоции?
- Классический подход к задаче классификации эмоций
- Классификация эмоций с применением deep learning
- Классификация эмоций по речи
- Аудиовизуальное распознавание эмоций
- Emotion AI от Empath определяет эмоции по голосу
- Распознавание эмоций с помощью сверточной нейронной сети
- Главные препятствия
- Описание проекта
- Описание данных
- Извлечение признаков
- Архитектура модели по умолчанию
- Мой эксперимент
- Разведочный анализ данных
- Наблюдение
- Повторение эксперимента
- Тест производительности
- Производительность новой модели
- Увеличение (аугментация)
- Мужчины, 5 классов
- Объединяем несколько методов
- Тестируем аугментацию на мужчинах
- Мужчины, 2 класса
- Заключение
Введение в задачу распознавания эмоций
Распознавание эмоций – горячая тема в сфере искусственного интеллекта. К наиболее интересным областям применения подобных технологий можно отнести: распознавание состояния водителя, маркетинговые исследования, системы видеоаналитики для умных городов, человеко-машинное взаимодействие, мониторинг учащихся, проходящих online-курсы, носимые устройства и др.
В этом году компания ЦРТ посвятила этой теме свою летнюю школу по машинному обучению. В этой статье я постараюсь дать краткий экскурс в проблему распознавания эмоционального состояния человека и расскажу и подходах к ее решению.

Что такое эмоции?
Эмоция – это особый вид психических процессов, которые выражают переживание человеком его отношения к окружающему миру и самому себе. Согласно одной из теорий, автором которой является российский физиолог П.К. Анохин, способность испытывать эмоции была выработана в процессе эволюции как средство более успешной адаптации живых существ к условиям существования. Эмоция оказалась полезной для выживаемости и позволила живым существам быстро и наиболее экономно реагировать на внешние воздействия.
Эмоции играют огромную роль в жизни человека и межличностном общении. Они могут быть выражены различными способами: мимикой, позой, двигательными реакциями, голосом и вегетативными реакциями (частота сердечных сокращений, артериальное давление, частота дыхания). Однако наибольшей выразительностью обладает лицо человека.
Каждый человек выражает эмоции несколько по-разному. Известный американский психолог Пол Экман, исследуя невербальное поведение изолированных племен в Папуа-Новой Гвинее в 70-х годах прошлого века, установил, что ряд эмоций, а именно: гнев, страх, печаль, отвращение, презрение, удивление и радость являются универсальными и могут быть поняты человеком, независимо от его культуры.
Люди способны выражать широкий спектр эмоций. Считается, что их можно описать как комбинацию базовых эмоций (например, ностальгия – это что-то среднее между печалью и радостью). Но такой категориальный подход не всегда удобен, т.к. не позволяет количественно охарактеризовать силу эмоции. Поэтому наряду с дискретными моделями эмоций, был разработан ряд непрерывных. В модели Дж. Рассела водится двумерный базис, в котором каждая эмоция характеризуется знаком (valence) и интенсивностью (arousal). Ввиду своей простоты модель Рассела в последнее время приобретает все большую популярность в контексте задачи автоматической классификации выражения лица.

Итак, мы выяснили, что если вы не пытаетесь скрыть эмоциональное возбуждение, то ваше текущее состояние можно оценить по мимике лица. Более того, используя современные достижения в области deep learning возможно даже построить детектор лжи, по мотивам сериала «Lie to me», научной основой которого послужили непосредственно работы Пола Экмана. Однако эта задача далеко не так проста. Как показали исследования нейробиолога Лизы Фельдман Барретт, при распознавании эмоций человек активно использует контекстную информацию: голос, действия, ситуацию. Взгляните на фотографии ниже, это действительно так. Используя только область лица, правильное предсказание сделать невозможно. В связи с этим для решения этой задачи необходимо использовать как дополнительные модальности, так и информацию об изменении сигналов с течением времени.

Здесь мы рассмотрим подходы к анализу только двух модальностей: аудио и видео, так как эти сигналы могут быть получены бесконтактным путем. Чтобы подступиться к задаче в первую очередь нужно раздобыть данные. Вот список наиболее крупных общедоступных баз эмоций, известных мне. Изображения и видео в этих базах были размечены вручную, некоторые с использованием Amazon Mechanical Turk.
| Название | Данные | Разметка | Год выпуска |
|---|---|---|---|
| OMG-Emotion challenge | aудио/видео | 7 категорий, valence/arousal | 2018 |
| EmotiW challenge | aудио/видео | 6 категорий | 2018 |
| AffectNet | изображения | 7 категорий, valence/arousal | 2017 |
| AFEW-VA | видео | valence/arousal | 2017 |
| EmotioNet challenge | изображения | 16 категорий | 2017 |
| EmoReact | aудио/видео | 17 категорий | 2016 |
Классический подход к задаче классификации эмоций
Наиболее простой способ определения эмоции по изображению лица основан на классификации ключевых точек (facial landmarks), координаты которых можно получить, используя различные алгоритмы PDM, CML, AAM, DPM или CNN. Обычно размечают от 5 до 68 точек, привязывая их к положению бровей, глаз, губ, носа, челюсти, что позволяет частично захватить мимику. Нормализованные координаты точек можно непосредственно подать в классификатор (например, SVM или Random Forest) и получить базовое решение. Естественно положение лиц при этом должно быть выровнено.

Простое использование координат без визуальной компоненты приводит к существенной потере полезной информации, поэтому для улучшения системы в этих точках вычисляют различные дескрипторы: LBP, HOG, SIFT, LATCH и др. После конкатенации дескрипторов и редукции размерности с помощью PCA полученный вектор признаков можно использовать для классификации эмоций.

Однако такой подход уже считается устаревшим, так как известно, что глубокие сверточные сети являются лучшим выбором для анализа визуальных данных.
Классификация эмоций с применением deep learning
Для того чтобы построить нейросетевой классификатор достаточно взять какую-нибудь сеть с базовой архитектурой, предварительно обученную на ImageNet, и переобучить последние несколько слоев. Так можно получить хорошее базовое решение для классификации различных данных, но учитывая специфику задачи, более подходящими будут нейросети, используемые для крупномасштабных задач распознавания лиц.
Итак, построить классификатор эмоций по отдельным изображениям достаточно просто, но как мы выяснили, мгновенные снимки не совсем точно отражают истинные эмоции, которые испытывает человек в данной ситуации. Поэтому для повышения точности системы необходимо анализировать последовательности кадров. Сделать это можно двумя путями. Первым способом является подача высокоуровневых признаков, полученных от CNN, классифицирующей каждый отдельный кадр, в рекуррентную сеть (например, LSTM) для захвата временной составляющей.
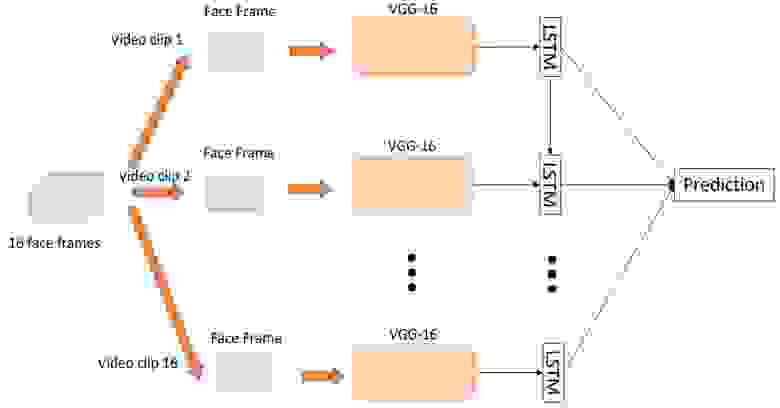
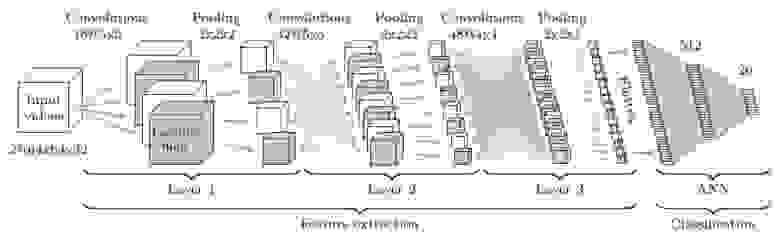
Второй способ заключается в непосредственной подаче последовательности кадров, взятых из видео с некоторым шагом, на вход 3D-CNN. Подобные CNN используют свертки с тремя степенями свободы, преобразующие четырехмерный вход в трехмерные карты признаков.
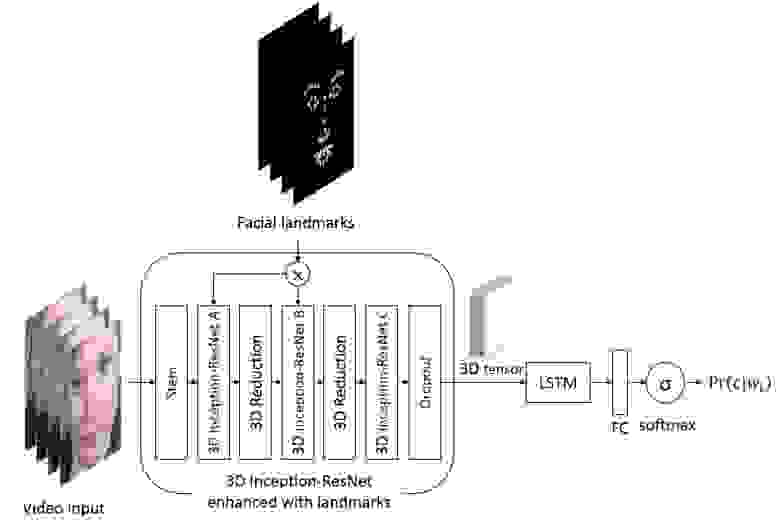
На самом деле в общем случае эти два подхода можно объединить, сконструировав вот такого монстра.
Классификация эмоций по речи
На основе визуальных данных можно с высокой точностью предсказывать знак эмоции, но при определении интенсивности предпочтительнее использовать речевые сигналы. Анализировать аудио немного сложнее ввиду сильной вариативности длительности речи и голосов дикторов. Обычно для этого используют не исходную звуковую волну, а разнообразные наборы признаков, например: F0, MFCC, LPC, i-вектора и др. В задаче распознавания эмоций по речи хорошо себя зарекомендовала открытая библиотека OpenSMILE, содержащая богатый набор алгоритмов для анализа речи и музыкальных сигналов. После извлечения, признаки могут быть поданы в SVM или LSTM для классификации.
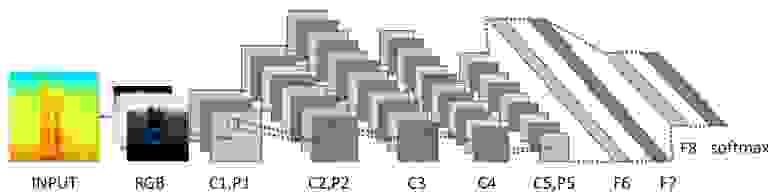
Однако в последнее время сверточные нейронные сети стали проникать и в область анализа звука, вытесняя устоявшиеся подходы. Для того чтобы их применить, звук представляют в виде спектрограмм в линейной или mel-шкале, после чего с полученными спектрограммами оперируют как с обычными двумерными изображениями. При этом проблема произвольного размера спектрограмм по временной оси элегантно решается при помощи статистического пулинга или за счет включения в архитектуру рекуррентной сети.
Аудиовизуальное распознавание эмоций
Итак, мы рассмотрели ряд подходов к анализу аудио- и видеомодальностей, остался заключительный этап – объединение классификаторов для вывода окончательного решения. Простейшим способом является непосредственное объединение их оценок. В этом случае достаточно взять максимум или среднее. Более сложным вариантом является объединение на уровне эмбеддингов для каждой модальности. Для этого часто применяют SVM, но это не всегда корректно, так как эмбеддинги могут иметь различную норму. В связи с этим были разработаны более продвинутые алгоритмы, например: Multiple Kernel Learning и ModDrop.
Ну и конечно стоит упомянуть о классе так называемых end-to-end решений, которые могут обучаться непосредственно на сырых данных от нескольких датчиков без всякой предварительной обработки.
В целом задача автоматического распознавания эмоций еще далека от решения. Судя по результатам прошлогоднего конкурса Emotion Recognition in the Wild, лучшие решения достигают точности порядка 60%. Надеюсь, что представленной в этой статье информации будет достаточно, для того чтобы попытаться построить собственную систему распознавания эмоций.
Источник
Emotion AI от Empath определяет эмоции по голосу
Определение эмоций человека по интонациям его голоса — уже относительно насыщенный рынок, на котором работают такие стартапы, как Affectiva, Beyond Verbal, Cogito и Realeyes, не говоря уже о том, что им интересуются и такие гиганты, как Amazon.
![]()
Потенциал у технологии большой — зная точное состояние человека можно изменить ответ умного помощника или человека в службе технической поддержки. Кроме того, понимание эмоция может помочь в мониторинге здоровья и обнаружении признаков некоторых заболевания, таких как, например, деменция или сердечная недостаточность.
Относительно новым участником в этом сегменте обнаружения эмоций является Empath, японский стартап, основанный в 2017 году. Он создал платформу, получившую название Emotion AI. ИИ компании способен автоматически определять одну из четырех эмоций — радость, гнев, спокойствие и печаль — в речи человека в режиме реального времени на любом языке в средах с высоким уровнем шума.
На основе Emotion AI уже работает система My Mood, позволяющая работникам отслеживать свое эмоциональное состояние и в целом определять его связь с погодой. А для разработчиков доступен Web Empath API, с помощью которого определение эмоций можно добавить в любое приложение или сервис.
До сих пор Web Empath AI преимущественно использовался в колл-центрах, где, по утверждению Empath, он сократил переработку менеджеров на 20%, а конверсию в продажи увеличил почти на 400%. Но в будущем, говорит стартап, его решения могут найти применение в видеоиграх, в роботах и даже в транспортных средствах. Недавно Empath заключил партнерское соглашение с компанией по производству игрушек Bocco, которая создала систему обмена сообщениями, предназначенную для детей, и с Utaka, которая делает лампу, подбирающую цвет под эмоции человека.
» data-medium-file=»https://i1.wp.com/apptractor.ru/wp-content/uploads/2019/09/1-1.jpg?fit=1024%2C1002&ssl=1″ data-large-file=»https://i1.wp.com/apptractor.ru/wp-content/uploads/2019/09/1-1.jpg?fit=740%2C724&ssl=1″ svg+xml,%3Csvg%20xmlns=’http://www.w3.org/2000/svg’%20viewBox=’0%200%20740%20724’%3E%3C/svg%3E» alt=»Emotion AI от Empath определяет эмоции по голосу» width=»740″ height=»724″ data-lazy-srcset=»https://i1.wp.com/apptractor.ru/wp-content/uploads/2019/09/1-1.jpg?w=1400&ssl=1 1400w, https://i1.wp.com/apptractor.ru/wp-content/uploads/2019/09/1-1.jpg?resize=640%2C626&ssl=1 640w, https://i1.wp.com/apptractor.ru/wp-content/uploads/2019/09/1-1.jpg?resize=1024%2C1002&ssl=1 1024w, https://i1.wp.com/apptractor.ru/wp-content/uploads/2019/09/1-1.jpg?resize=768%2C751&ssl=1 768w, https://i1.wp.com/apptractor.ru/wp-content/uploads/2019/09/1-1.jpg?resize=2048%2C2003&ssl=1 2048w» data-lazy-sizes=»(max-width: 740px) 100vw, 740px» data-recalc-dims=»1″ data-lazy-src=»https://i1.wp.com/apptractor.ru/wp-content/uploads/2019/09/1-1.jpg?resize=740%2C724&ssl=1″/>
The color changes in response to user emotions. (PRNewsFoto/Smartmedical Corp.)
Источник
Распознавание эмоций с помощью сверточной нейронной сети
Распознавание эмоций всегда было захватывающей задачей для ученых. В последнее время я работаю над экспериментальным SER-проектом (Speech Emotion Recognition), чтобы понять потенциал этой технологии – для этого я отобрал наиболее популярные репозитории на Github и сделал их основой моего проекта.
Прежде чем мы начнем разбираться в проекте, неплохо будет вспомнить, какие узкие места есть у SER.
Главные препятствия
Описание проекта
Использование сверточной нейронной сети для распознавания эмоций в аудиозаписях. И да, владелец репозитория не ссылался ни на какие источники.
Описание данных
Есть два датасета, которые использовались в репозиториях RAVDESS и SAVEE, я только лишь адаптировал RAVDESS в своей модели. В контекста RAVDESS есть два типа данных: речь (speech) и песня (song).
- 12 актеров и 12 актрис записали свою речь и песни в своем исполнении;
- у актера #18 нет записанных песен;
- эмоции Disgust (отвращение), Neutral (нейтральная) и Surprises (удивленние) отсутствуют в «песенных» данных.
Разбивка по эмоциям:
Диаграмма распределения эмоций:
Извлечение признаков
Когда мы работаем с задачами распознавания речи, мел-кепстральные коэффициенты (MFCCs) – это передовая технология, несмотря на то, что она появилась в 80-х.
Эта форма определяет, каков звук на выходе. Если мы можем точно обозначить форму, она даст нам точное представление прозвучавшей фонемы. Форма речевого тракта проявляет себя в огибающей короткого спектра, и работы MFCC – точно отобразить эту огибающую.
Мы используем MFCC как входной признак. Если вам интересно разобраться подробнее, что такое MFCC, то этот туториал – для вас. Загрузку данных и их конвертацию в формат MFCC можно легко сделать с помощью Python-пакета librosa.
Архитектура модели по умолчанию
Автор разработал CNN-модель с помощь пакет Keras, создав 7 слоев – шесть Con1D слоев и один слой плотности (Dense).
Автор закомментировал слои 4 и 5 в последнем релизе (18 сентября 2018 года) и итоговый размер файла этой модели не подходит под предоставленную сеть, поэтому я не смогу добиться такого же результат по точности – 72%.
Модель просто натренирована с параметрами batch_size=16 и epochs=700 , без какого-либо графика обучения и пр.
Здесь categorical_crossentropy это функция потерь, а мера оценки – точность.
Мой эксперимент
Разведочный анализ данных
В датасете RAVDESS каждый актер проявляет 8 эмоций, проговаривая и пропевая 2 предложения по 2 раза каждое. В итоге с каждого актера получается 4 примера каждой эмоции за исключением вышеупомянутых нейтральной эмоции, отвращения и удивления. Каждое аудио длится примерно 4 секунды, в первой и последней секундах чаще всего тишина.
Наблюдение
После того как я выбрал датасет из 1 актера и 1 актрисы, а затем прослушал все их записи, я понял, что мужчины и женщины выражают свои эмоции по-разному. Например:
- мужская злость (Angry) просто громче;
- мужские радость (Happy) и расстройство (Sad) – особенность в смеющемся и плачущем тонах во время «тишины»;
- женские радость (Happy), злость (Angry) и расстройство (Sad) громче;
- женское отвращение (Disgust) содержит в себе звук рвоты.
Повторение эксперимента
Автор убрал классы neutral, disgust и surprised, чтобы сделать 10-классовое распознавание датасета RAVDESS. Пытаясь повторить опыт автора, я получил такой результат:
Однако я выяснил, что имеет место утечка данных, когда датасет для валидации идентичен тестовому датасету. Поэтому я повторил разделение данных, изолировав датасеты двух актеров и двух актрис, чтобы они не были видны во время теста:
- актеры с 1 по 20 используются для сетов Train / Valid в соотношении 8:2;
- актеры с 21 по 24 изолированы от тестов;
- параметры Train Set: (1248, 216, 1);
- параметры Valid Set: (312, 216, 1);
- параметры Test Set: (320, 216, 1) — (изолировано).
Я заново обучил модель и вот результат:
Тест производительности
Из графика Train Valid Gross видно, что не происходит схождение для выбранных 10 классов. Поэтому я решил понизить сложность модели и оставить только мужские эмоции. Я изолировал двух актеров в рамках test set, а остальных поместил в train/valid set, соотношение 8:2. Это гарантирует, что в датасете не будет дисбаланса. Затем я тренировал мужские и женские данные отдельно, чтобы провести тест.
- Train Set – 640 семплов от актеров 1-10;
- Valid Set – 160 семплов от актеров 1-10;
- Test Set – 160 семплов от актеров 11-12.
Опорная линия: мужчины
- Train Set – 608 семплов от актрис 1-10;
- Valid Set – 152 семпла от актрис 1-10;
- Test Set – 160 семплов от актрис 11-12.
Опорная линия: женщины
Как можно заметить, матрицы ошибок отличаются.
Мужчины: злость (Angry) и радость (Happy) – основные предугаданные классы в модели, но они не похожи.
Женщины: расстройство (Sad) и радость (Happy) – основыне предугаданные классы в модели; злость (Angry) и радость (Happy) легко спутать.
Вспоминая наблюдения из Разведочного анализа данных, я подозреваю, что женские злость (Angry) и радость (Happy) похожи до степени смешения, потому что их способ выражения заключается просто в повышении голоса.
Вдобавок ко всему, мне интересно, что если я еще больше упрощу модель, остави только классы Positive, Neutral и Negative. Или только Positive и Negative. Короче, я сгруппировал эмоции в 2 и 3 класса соответственно.
- Позитивные: радость (Happy), спокойствие (Calm);
- Негативные: злость (Angry), страх (fearful), расстройство (sad).
3 класса:
- Позитивные: радость (Happy);
- Нейтральные: спокойствие (Calm), нейтральная (Neutral);
- Негативные: злость (Angry), страх (fearful), расстройство (sad).
До начала эксперимента я настроил архитектуру модели с помощью мужских данных, сделав 5-классовое распознавание.
Я добавил 2 слоя Conv1D, один слой MaxPooling1D и 2 слоя BarchNormalization; также я изменил значение отсева на 0.25. Наконец, я изменил оптимизатор на SGD со скоростью обучения 0.0001.
Для тренировки модели я применил уменьшение «плато обучения» и сохранил только лучшую модель с минимальным значением val_loss . И вот каковы результаты для разных целевых классов.
Производительность новой модели
Мужчины, 5 классов
Мужчины, 2 класса
Мужчины, 3 класса
Увеличение (аугментация)
Когда я усилил архитектуру модели, оптимизатор и скорость обучения, выяснилось, что модель по-прежнему не сходится в режиме тренировки. Я предположил, что это проблема количества данных, так как у нас имеется только 800 семплов. Это привело меня к методам увеличения аудио, в итоге я увеличил датасеты ровно вдвое. Давайте взглянем на эти методы.
Мужчины, 5 классов
Динамическое увеличение значений
Настройка высоты звука
Добавление белого шума
Заметно, что аугментация сильно повышает точность, до 70+% в общем случае. Особенно в случае с добавлением белого, которое повышает точность до 87,19% – однако тестовая точность и F1-мера падают более чем на 5%. И тут мне ко пришла идея комбинировать несколько методов аугментации для лучшего результата.
Объединяем несколько методов
Белый шум + смещение
Тестируем аугментацию на мужчинах
Мужчины, 2 класса
Белый шум + смещение
Для всех семплов
Белый шум + смещение
Только для позитивных семплов, так как 2-классовый сет дисбалансированный (в сторону негативных семплов).
Настройка высоты звука + белый шум
Для всех семплов
Настройка высоты звука + белый шум
Только для позитивных семплов
Заключение
В конце концов, я смог поэкспериментировать только с мужским датасетом. Я заново разделил данные так, чтобы избежать дисбаланса и, как следствие, утечки данных. Я настроил модель на эксперименты с мужскими голосами, так как я хотел максимально упростить модель для начала. Также я провел тесты, используя разные методы аугментации; добавление белого шума и смещение хорошо зарекомендовали себя на дисбалансированных данных.
Источник